연구 개요
해당 연구는 보완된 연구로 해당 보고서에는 공개 가능한 부분만 정리하였다.
연구 일정
2021
-
10. Patent & Software MultiRobot-Allocation Simulator
-
10. Paper Generating Multi-agent Patrol Areas by Reinforcement Learning
-
11. Paper Analyzing Conflicting Objectives in Deep Reinforcement Learning...
-
12. SCI Paper Scheduling PID Attitude and Position Control Frequencies...
-
12. SCI Paper Cooperative Multi-Robot Task Allocation with Reinforcement Learning
-
12. Evaluation First Year Final
2022
-
06. Paper Automatic Analysis of Mobile Robot Decision Process...
2023
-
02. Paper Sample Filtering for Efficient Online Distillation...
- 07. Software : CPS Core
-
08. Paper: TBD
-
09. Evaluation Second Year Mid-Term
-
12. SCI Paper: TBD
-
12. SCI Paper: TBD
논문 리스트
Message Passing with Gating Mechanisms in Multi-agent Reinforcement Learning
It is important to consider the subjectivity of messages in multi-agent reinforcement learning (MARL). Based
on the assumption that the encoded information is a rather subjective information of the agent encode it, we tackle the problem of
handling objective and subjective information in MARL.
Sample Filtering for Efficient Distillation in Reinforcement Learning
In this paper, we propose an on-line distillation framework with sample filtering
based on teacher Q-error quantiles. We evaluate the framework in control tasks and show that selecting
proper samples not only increases performance but also reduces the training time.
Automatic Analysis of Mobile Robot Decision Process with Layer-wise Relevance Propagation in Reinforcement Learning
It is challenging to explain the internal mechanisms of reinforcement learning due to the `black
box' nature of deep neural networks. Therefore, we propose an automated analysis method to understand
decision-making processes of reinforcement learning models. Specifically, we identify important input features
for a decision through layer-wise relevance propagation.
Analyzing Conflicting Objectives in Deep Reinforcement Learning-based Target Tracking System
In this paper, we build a target tracking system based on deep reinforcement learning. Then, we analyze the trade-offs between target following and obstacle avoidance by training the model with varying weights of two objectives. We perform experiments in a virtual simulation environment. The experimental results show that the model exhibits different behaviors depending on the weights of the objectives.
Generating Multi-agent Patrol Areas by Reinforcement Learning
We designed reinforcement learning environment for distributed patrolling agents. In the partially observable environment, the agents take actions for each one's interest and the non-stationary problem in multi-agent setting encourages the agents not to invade other agent's region. In our environment, the patrolling routes for the agents are generated implicitly.
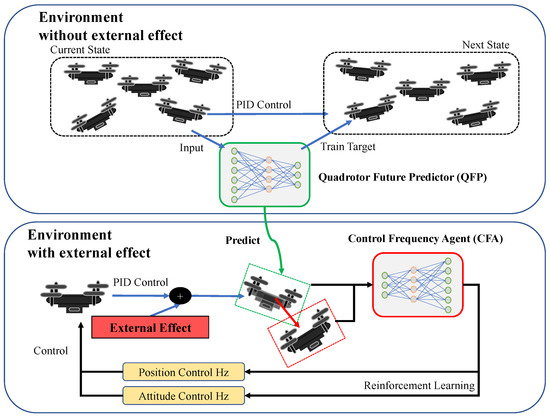
Scheduling PID attitude and position control frequencies for time-optimal quadrotor waypoint tracking under unknown external disturbances
|
Sensors |
Cheongwoong Kang, Bumjin Park, and Jaesik Choi, 2021
We suggest a method to schedule the PID position and attitude control frequencies for time-optimal quadrotor waypoint tracking. The method includes (1) a Control Frequency Agent (CFA) that finds the best control frequencies in various environments, (2) a Quadrotor Future Predictor (QFP) that predicts the next state of a quadrotor, and (3) combining the CFA and QFP for time-optimal quadrotor waypoint tracking under unknown external disturbances.
Cooperative Multi-Robot Task Allocation with Reinforcement Learning
This paper deals with the concept of multi-robot task allocation, referring to the assignment of multiple robots to tasks such that an objective function is maximized. The performance of existing meta-heuristic methods worsens as the number of robots or tasks increases. To tackle this problem, a novel Markov decision process formulation for multi-robot task allocation is presented for reinforcement learning.