Source Identification for Generative Models
Can we provide the source of generation?
This is a problem formulation for finding the source of generation.
1. Introduction
In the training of a deep neural network, we collect a large amount of data and process the data only for training purposes.
The pre-process mostly decreases the amount of information to abandon irrelevant information in data and provides compact representations for the training data by discarding information which is not helpful for the training. The process of filtering information is essential to properly match the training objective efficiently and robustly
Creating safe AGI that benefits all of humanity
- From : ???
The source of the sentence is website of OpenAI ©. As the source is entangled with the sentence, we get additional information such as
- The underlying context of the sentence
- The factuality of the sentence
- The meaning of AGI (if you are in the AI field.)
Even though there are benefits of knowing the source location of the data, the source link of data may not required to train neural networks
Only for the training purpose, discarding irrelevant information is beneficial. But, we don't know made the information.
Within the progress of generative models, another training mechanism is required to ensure the safety issues for both models and data.
2. Problem Definition
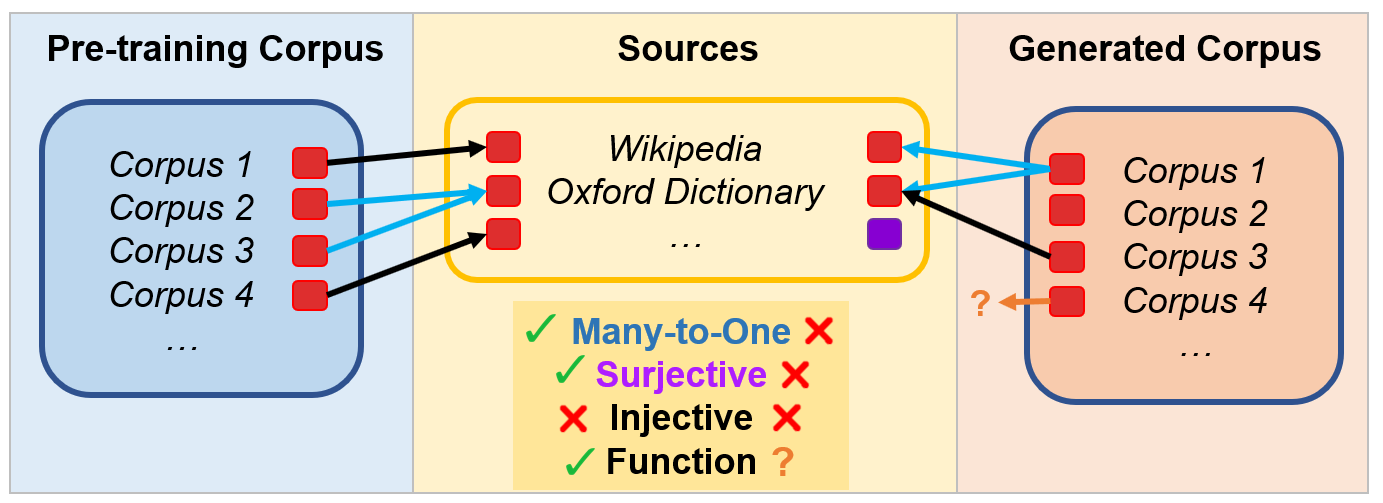
The fundamental problem is the identification of the source of a corpus called as source identification problem (SIP). Given a corpus, scrapped from a website or generated by chatGPT, we identify the original source of the corpus. The casual link of source $S$, text $x$, generator $G$, and the generated text $\hat{x}$ is as follows:
\[\begin{equation} s \rightarrow x \rightarrow G \rightarrow \hat{x} \end{equation}\]The SIP is a identification problem of the source of the text $x$ or the generated text.
\[\begin{gather} x \rightarrow s \\ \hat{x} \leftarrow s \end{gather}\]However, it is a ill-posed problem as multiple sources are possible. As finding the source from corpus is neither injective nor surjective. For example, the corpus “apple is delicious” is a quite common sentence and lots of websites can include the corpus (non-injective) and the corpus “fine apple is pricked by pineapple.” may not have the source, but generated by a generative model (non-surjective). In addition if the text is slightly changed by adding “The”, the corpora have almost same meaning and the sources must be equal.
\[\begin{equation} \hat{x} \rightarrow \{s_1, s_2, \cdots\} \end{equation}\]As such, the source verification problem is a problem of generating possible multiple sources of a given corpus. Although, functionally learning the Equation (4) can solve the source identification problem, we don’t know the actual meaning of mapping corpora to sources. One reason is that a corpus has semantic and lexical information and two different corpora can have exactly same information.
3. Building Blocks of SIP
Before proceeding on the detailed discussion on SIP, we discuss on the proper definitions for sources and corpora. C-corpora (copyrighted-corpora) are semantic or lexical contents in the source. Source is the genuine location of c-corpora.
3.1 Copyrighted-Corpora
Which information
The copyrighted-corpora is copyrighted a corpora in two perspectives, semantic anc lexical.
Ex) Creating safe AGI that benefits all of humanity
- Semantic : AI system benefits all people
- Lexical : Creating, safe, AGI, benefit, humanity
As such, we have the following properties for copyrighted-corpora
-
Semantic Source: the semantic meaning of a copyrighted-corpus comes from the source -
Lexical Source: the lexical information of a copyrighted-corpus comes from the sentence
Which Sources
One additional property is that a corpus can be formed by multiple sources of corpora. For example, we can combine two corpus from OpenAI and Meta each to make the following sentence. [© from Meta’s Action]
Ex) Creating safe AGI that benefits all of humanity by keeping people safe and making a positive impact.
Definition of Copyrighted-Corpora
Definition [Copyrighted-Corpora]
Copyrighted-corpora is a corpora whose lexical or semantic meaning is similar with corpus from a source or combined by multiple corpus originated from possibly multiple corpus.
This definition is similar to how we think about copyright. Even though a sentence is not totally matched with any sentence in training dataset, Multiple sentences from other sources can be used to form the sentence by extracting (1) semantic information and (2) lexical information.
3.2 Source
Source is the origin of sentences. The origin could be companies, persons, websites which have the copyright of the sentences. We list some possible sources.
-
Company: The company who has the copyright of overall contents (OpenAI, Meta, …) -
Person: The labeled person who talked or wrote sentences (Martin Ruther King, …) -
Website: The well known website (Wiki, Reddit, … ) -
Hyperlinks: Specific link of website (https://distill.pub/2020/circuits/)
Related Work
There are several ways to provide the source link of generated sentences.
- Generation : directly generate the sources with labels.
- Watermark: inject identifiable keys to sentences which is visible in the inference steps
- Web search engine : search websites with a GPT and provide links
- Prompt tuning : ask GPT to provide the source
| Methods | Procedure | Pros | Cons |
|---|---|---|---|
| Generation | $G \rightarrow \hat{x} \rightarrow \hat{G} \rightarrow s$ | Easily learnable | in-scalable, hard to believe |
| Watermark | $G \rightarrow (s), h \rightarrow \hat{x}$ | Only requires inference steps | Unclear how to apply it to NLP.(Fourier Frequency) |
| Web Search | $G \rightarrow [s_1,s_2,\cdots ] \rightarrow s_k \rightarrow \hat{x}$ | Direct identification | does not provide model’s knowledge in inference |
| Prompt Tuning | $G \rightarrow \hat{x}, S$ | The most easiest way | hard to believe |
Identification via Generation
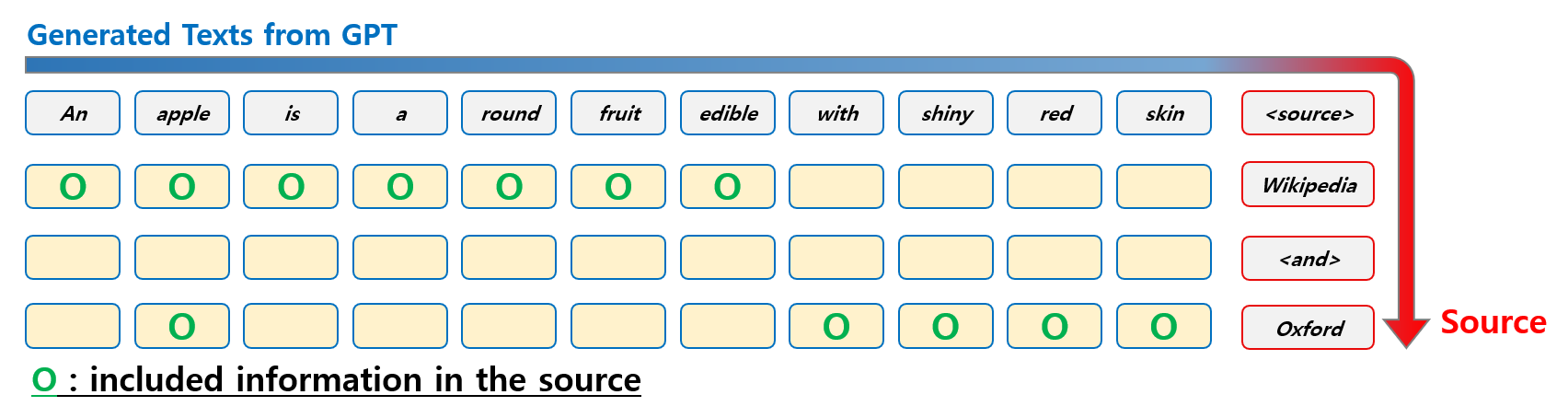
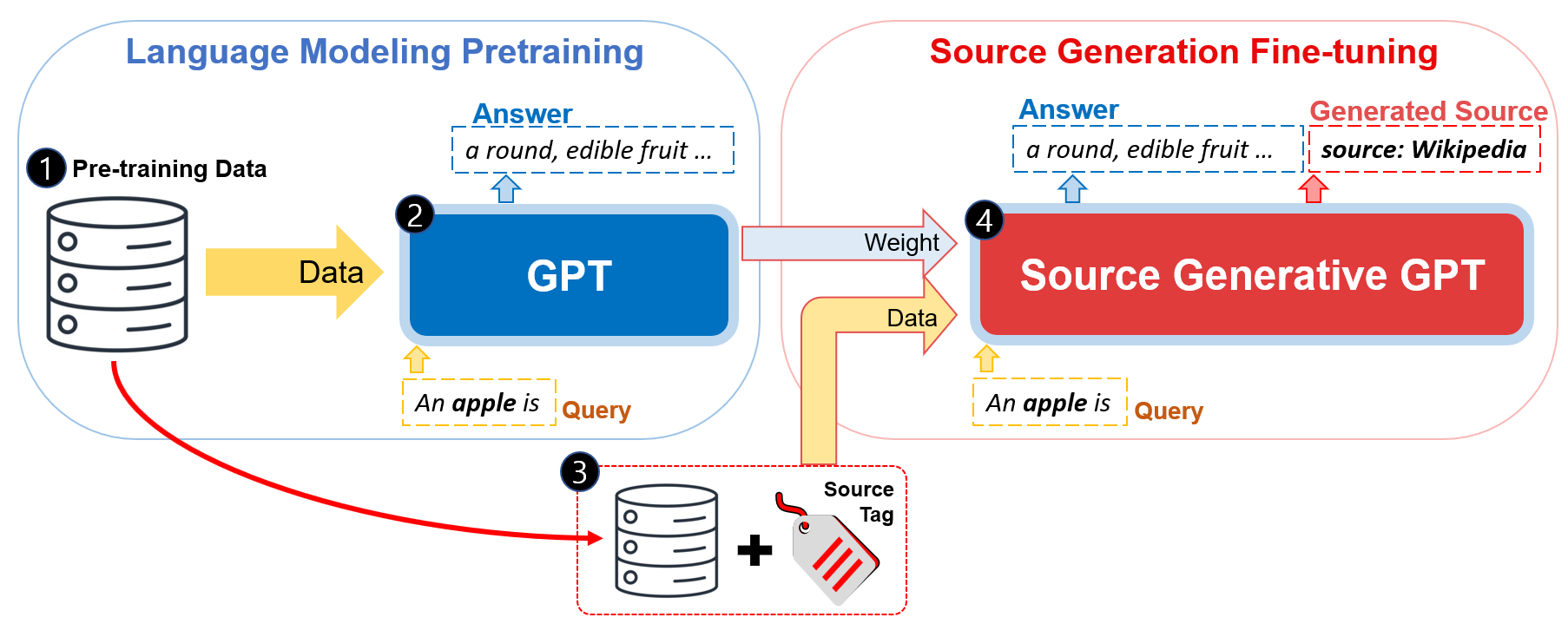
The most simple way is to train another GPT model to recover the source link of the sentences. When a GPT model $G$ generates sentences $\hat{x}$, another GPT-like model generates the description of sources $S$.
\[G \rightarrow \hat{x} \rightarrow \hat{G} \rightarrow s\]Watermark
Previous work is done in vision domain which has continuous representations.
Watermark is a simple way to encode information in the representation and previously explored in diffusion models
WebGPT and Bing
One way to prevent the copyright issues is to make a model directly uses the corpus in a source in the inference procedure. This method can provide the source link to the end users. Recently WebGPT uses the Bing search engine to improve the factuality and to provide the external links
GPT Prompt tuning
One direct way is to ask the model to provide the source link [related post].
\[G \rightarrow \hat{x}, S\]Please provide sources for the previous answer
Please provide URL sources
Please provide 10 URL sources
Methods
We propose Source generation fine-tuning framework to learn the auxiliary task.
Watermark
Defender: Watermark 🌊
For content $x$, watermark $b$ is given to protect the content. The defender encode an invisible watermark in the content with encoder $E$ takes the content and watermark to generate a watermarked information $x_{wm}$:
\[x_{wm} = E(x,b)\]The decoder $D$ takes $x_{wm}$ and recovers the watermark $b$.
Attacker : Distort Watermark 👾
The attacker tries to modify the watermarked $w_{wm}$ image by attacked content $\tilde{x}_{wm}$ with modifier $g$ to remove the encoded information $b$ in it.
\[\tilde{x}_{wm} = g(w_{wm})\]The goal of the attacker is to minimize the recovery of watermark in the content.
\[\min L(b, D(\hat{x}_{wm}))\]where $L$ is a matching loss such as bitwise accuracy.
Provenance Detection
Watermark videos
pseudorandom function $f(w_{t-c+1}, \cdots, w_{t-1}, i)$ maps the latest token $c$ to $r_{t,i} \in [0,1]$. This is pseudo probability distribution.
Parameter Efficient Fine-tuning
2023.09.23 : Given A Language Model and Any Text, Verify the Source Prediction Performance
Let $f$ be a generative language model and $\theta$ be the trained parameters with large corpus. Our goal is to verify the source $y$ of text tokens $x=(x_1, x_2, \cdots, x_n)$. To decode the source of text, we use the logits of decoder outputs which we call traced logits of text $x$.
\[T(x) = (\hat{p}_2, \hat{p}_3, \cdots, \hat{p}_{n+1})\]where $\hat{p}_i = P( \cdot \vert x_1, x_2, \cdots, x_i ; \theta) \in \mathbb{R}^{V}$ is the conditional probability distribution over vocabulary $V$ given previous tokens.
This logits are different from previous watermark based data provenance. As the watermark assumes that the generated text is decoded output of the generative model, while our method does not have such assumption. Therefore, we consider how a generative model encodes any text.
2023.10.09
모델이 문장에 대한 정보를 암기하고 있으면서, 특정 레이블에 대한 확률값이 높은 경우, 해당 원천 소스에 대한 출처의 확신이 높아진다.
네거티브 샘플의 종류에 대해서 정보를 판단해야 한다. 예로, 완벽하게 일치하는 문장만 포함하는 경우부터, 문장의 의미가 비슷한 경우, 그리고 사용하는 어휘가 비슷한 경우를 생각할 수 있다. 또한, 해당 원천 데이터에 대해서 원본과 GPT 이 샘플링을 한 것을 비교하는 경우도 가능하다. 이는 원천소스 탐지에 대해서 일반화의 수준이 요구하는 정도에 따라서 다르며, 이로 인해서 예측 모델의 종류와 성능도 달라져야 한다는 것을 의미한다. Soft한 Negative Sample 을 사용하는 경우 단순한 모델로도 원천소스를 탐지할 수 있다. 그러나, 원천소스가 비슷한 데이터라면, 두 클래스를 구분하는 것은 쉬운 일이 아니며, 어떠한 특징으로부터 구분할지 고민해야 한다. 클래시파이어는 결국,
2023.10.10 : 학습데이터의 확장 : XML 데이터 분석 및 추가
====================
** INCLUDE **
LF-Amazon-131K
trn
From label 294805 131073
294805it [00:00, 1010858.06it/s]
294805it [00:00, 2783772.85it/s]
num inputs: 294805
num outputs: 294805
['Methodical Bible study: A new ', 'GeoPuzzle U.S.A. and Canada - ']
['4315:1.0\n', '112532:1.0 113827:1.0\n']
====================
Wikipedia-500K
trn
From label 1813391 501070
1813391it [00:11, 163675.08it/s]
1813391it [00:00, 2942573.18it/s]
num inputs: 1813391
num outputs: 1813391
['Anarchism redirect2|anarchis', 'Albedo other uses use dm']
['81199:1.0 83757:1.0 83805:1.0 ', '144177:1.0 144212:1.0 182348:1']
2023.10.11 : Cross Entropy with Increasing Number of Labels 실험
단순하게, Classifier 를 학습한 결과를 일단 모으고, 학습 방법을 점진적으로 개선해야 한다. 결국 SIP 문제를 XML 문제에 가깝기 때문이다. 그 전에, 단순 Classifier 에 대해서 학습한 결과를 Report하는 것은 필요하다. 이 때, CrossEntropy Loss 를 한 것과 Binary Cross Entropy Loss 를 사용한 것을 비교해야 한다.
Let $S_i$ be the set of positive labels and negative labels in a shortlist $N_i$. The standard training loss for classification problem is cross entropy loss (CE). Cross entropy loss is defined as follows:
\[\mathcal{L}_{CE} = \sum_i^N \sum_{\ell \in S_i} y_{i\ell} \log \frac{\exp{(W_{\ell} z_i)}}{\sum_{\ell' } \exp{ (W_{\ell'} z_i) }}\]With the PG19 datasets with 100 samples per label each, we evaluate the basic ReLU based encoder for the classification problem.
We observe that the training is not scalable with the increasing number of labels. We conclude two things in this experiment
- (Suitable Loss) CE loss architecture is not suitable for source identification problem with increased number of sources.
- (Model Scalability) As the model size increases, the classification training is better on average.
- (Generalization) Generalization over source identification may not be feasible.
Training
Evaluation
변경된 Loss : CE –> BCE
Binary cross entropy loss is defined as follows:
\[\mathcal{L}_{BCE} = \sum_i^N \sum_{\ell \in S_i} y_{i\ell} \log (\sigma (W_{\ell} z_i )) + (1-y_{i\ell}) \log (1- \sigma (W_{\ell} z_i ))\]where $\sigma$ is sigmoid function $\sigma(x) = \frac{1}{1+\exp{(-x)}}$.
입력값 (GPT Hiddens)에 대한 고민
중요질문 : 학습이 가능한 것은 단어에 대한 유의미한 Feature 이기 때문인가? 아니면, Class 에 대해서 구분된 표현 공간을 지니기 때문인가? 즉, 문장을 기억하지 않더라도, 단순히 표현이 다르기 때문에 원천 소스를 찾는 게 가능한가?
GPT 모델이 원천 소스에 대해서 학습을 해서, 이후에 나오는 단어에 대해서 특징을 가지면서, 클래스별로 구분될 수 있다면, 원천소스를 찾는데 사용될 수 있다. 만일, GPT 모델이 해당 문장에 대해서 원천소스를 기억할만큼 정보량을 지니고 있다면 GPT 모델이 원천소스에 대해서 원천을 맵핑할만큼 유의미한 표현 공간을 지니는가?
- 원천을 나눠서 기억할만큼 서로 다른 표현 공간이다.
- 원천을 기억할만큼 유의미한 표현이다.
2023.10.13 논문 학습 구조 확정
1. 학습 세팅에 따른 성능 비교
1.1 단순 학습
BCE / CE에 대해서 논의하면서 두 학습 결과를 비교한다.
Increasing Number of Labels
Increasing Number of Words
Increasing Model Size
1.2 DeepXML 세팅
BCE에 대해서 추가적인 추가적인 학습을 진행할 경우 성능을 체크한다.
추가적인 학습은
1. 클러스터링을 통한 가짜 레이블 학습
2. Hard Negative Sampling
3. Training (DeepXML Framework)
Increasing Number of Labels
Increasing Number of Words
Increasing Model Size
* Note 1 : 모든 원천 데이터에 대해서 1차적인 학습을 진행할 수 있다.
* Note 2 : 이후, 추가적인 원천 데이터에 대해서 Finetuning 할 수 있다.
2. Encoder Ablation
* Simplest
* Deep MLP
* RNN
* Transformer Encoder
2023.10.13 : XML Literature Review
최근 연구된 XML에 대해서 내용을 정리하고, SIP 논문에 적을 내용을 소개한다.
As the training of source identification is not scalable with CE loss, the alternative loss is binary cross entropy loss (BCE) which is widely used in one-versus-all training framework [1,2,3] and in the field of extreme classification (EC) or extreme multi-label classification (XML). Deep learning-based XML methods have three properties in common : feature learning, negative label shortlisting, and classifier training [3]. We follow the XML training framework to train the source identification problem with integer labels. We do not utilize the label features, for example, the book name is not used.
Although recent works utilizes the label features to handle the lack of training samples [5,6,7], source identification could not directly use label features. As the input embedding GPT hidden representations are not sentence embeddings and the similarity between the labels and inputs are not guaranteed. Therefore, SIP problem is EC problem without label features.
AttentionXML forms a tree for label features [6]. SiameseXML enhanced zero-shot Siamese architecture to few-shot classification problem [7]. Renee propose optimization loss to stablize the training and increase the size of training to the fart more extreme number of labels (1B) [2]. DEXA [4] use additional parameters to complement the gap of pure label feature embeddings.
[1] Rifkin, Ryan, and Aldebaro Klautau. “In defense of one-vs-all classification.” The Journal of Machine Learning Research 5 (2004): 101-141.
[2] Jain, Vidit, et al. “Renee: END-TO-END TRAINING OF EXTREME CLASSIFICATION MODELS.” Proceedings of Machine Learning and Systems 5 (2023). (Renee)
[3] Dahiya, Kunal, et al. “Deepxml: A deep extreme multi-label learning framework applied to short text documents.” Proceedings of the 14th ACM International Conference on Web Search and Data Mining. 2021. (DeepXML)
[4] Dahiya, Kunal, et al. “Deep Encoders with Auxiliary Parameters for Extreme Classification.” Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2023. DEXA
[5] Jiang, Ting, et al. “Lightxml: Transformer with dynamic negative sampling for high-performance extreme multi-label text classification.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 35. No. 9. 2021. (LightXML)
[6] You, Ronghui, et al. “Attentionxml: Label tree-based attention-aware deep model for high-performance extreme multi-label text classification.” Advances in Neural Information Processing Systems 32 (2019). (AttentionXML)
[7] Dahiya, Kunal, et al. “Siamesexml: Siamese networks meet extreme classifiers with 100m labels.” International Conference on Machine Learning. PMLR, 2021. (SiameseXML)
[8] @Misc{Bhatia16, author = {Bhatia, K. and Dahiya, K. and Jain, H. and Kar, P. and Mittal, A. and Prabhu, Y. and Varma, M.}, title = {The extreme classification repository: Multi-label datasets and code}, url = {http://manikvarma.org/downloads/XC/XMLRepository.html}, year = {2016} }
2023.10.16 : Gathering Hiddens
GPT Hidden의 분포에 대한 분석/원천소스 맵핑을 학습하므로, 일단 GPT Hiddens (Vocab 전 마지막 표현)를 모아두고, prediction task 만 따로 학습한다.
XMl과 GPT Hiddens 를 결합하는 경우 메모리가 너무 많이 사용된다. 예로 PG19 데이터의 경우, 20000개가 넘는 레이블이 있는데, 레이블 당 100개씩 데이터를 얻는 경우, (2,000,000, Tokens, Dims) 사이즈의 메모리를 저장해야 한다. 따라서 레이블 1000개에 대해서 100개의 샘플을 모으고, CE Loss를 Binary CE 로 변경한 것과, Renee 에서 제안한 Loss까지 써본다.
| Models | Amazon131K | PG19 | Wikipedia500 |
|---|---|---|---|
Pythia-70m |
✅ | ✅ | |
Pythia-160m |
✅ | - | |
Pythia-410m |
✅ | - | |
Pythia-1b |
✅ | ||
Pythia-1.4b |
✅ | ||
Pythia-2.8b |
✅ | ||
Pythia-6.9b |
✅ | ||
Pythia-12b |
✅ | ||
LLama-chat-7b |
- | ||
LLama-7b |
- | ||
LLama-chat-13b |
- | ||
LLama-13b |
- | ||
GPT2-XL |
- | ||
GPT2-XL |
- | ||
OPT-350m |
- |
Data stats
-
PG19 (pythia pretraining data)
- labels: 28,602 (raw data)
- inputs : each book
-
Amazon131K (classification dataset)
- labels: 131,073
- inputs: 294,805
-
Wikipedia500 (classification dataset)
- labels: 501,070
- inputs: 1,813,391
