뉴런 - 2. 아키텍처
딥러닝은 여러가지 구조를 가지고 있다. 각 구조들에 대해서 뉴런은 어떤 정보를 담고 있을까?
3-2 MLP 뉴런
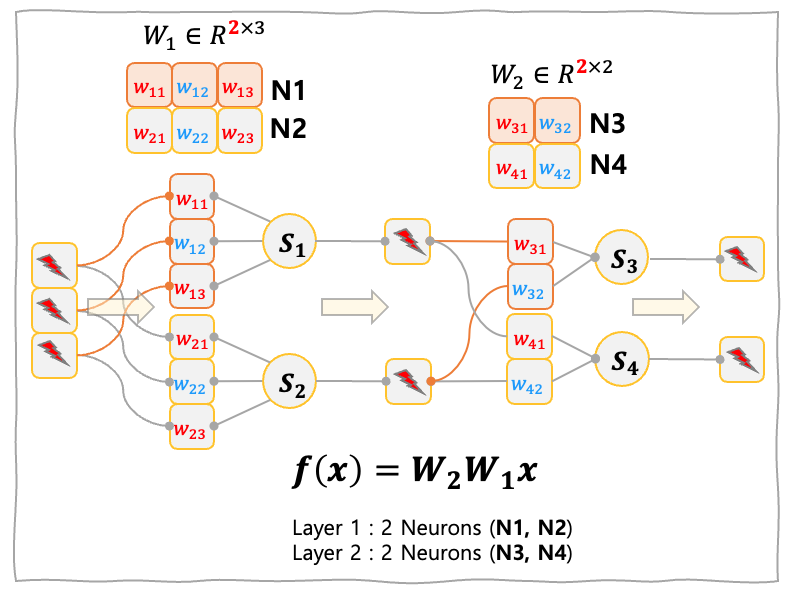
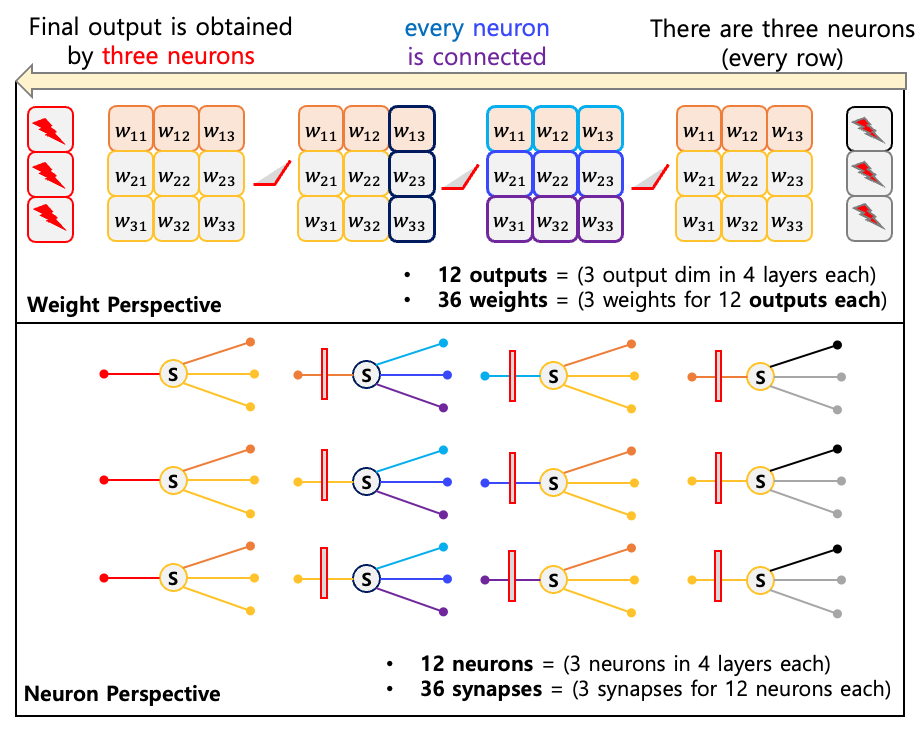
가장 간단한 형태인 $W \in \mathbb{R}^{m\times n}$ 매트릭스를 곱하는 선형 모델을 살펴보자.
\[y=Wx\]선형모델은 입력 벡터 $x\in \mathbb{R}^{n}$ 에 대해서 $m$ 개의 독립적인 weight vector 들이 각각 내적한 결과물로 생각할 수 있다.
- 📌 뉴런 개수 : $m$
- 📌 뉴런 당 시냅스 개수 : $n$
- 📌 전체 시냅스 개수 : $m\times n$
3-3 CNN 뉴런
가정: 모델 Weight 형태 2D Conv (out_channels, in_channels, kernel, kernel)
2D convolutional layer의 경우 weight 벡터를 다음과 같은 형태를 띈다. 여기서 out_channel 이 뉴런을 구분하는 역할을 하며, kernel은 입력에 대한 2차원적 위치 정보를 담는 역할을 한다. 선형모델의 뉴런과는 다르게 합성곱 연산을 하므로, 입력의 부분들을 Stride 만큼 돌리면서 활성화를 한다. 그러나 뉴런의 개수는 단순히 out_channel 개수이다. 극단적으로 아웃채널의 개수가 1개라면, 입력 채널의 개수에 상관없이 뉴런의 개수는 1개이다.
- 📌 뉴런 개수 : out_channels
- 📌 뉴런 당 시냅스 개수 : $\text{out_channels} \times \text{kernel} \times \text{kernel}$
- 📌 전체 시냅스 개수 : $\text{out_channels} \times \text{out_channels} \times \text{kernel} \times \text{kernel}$
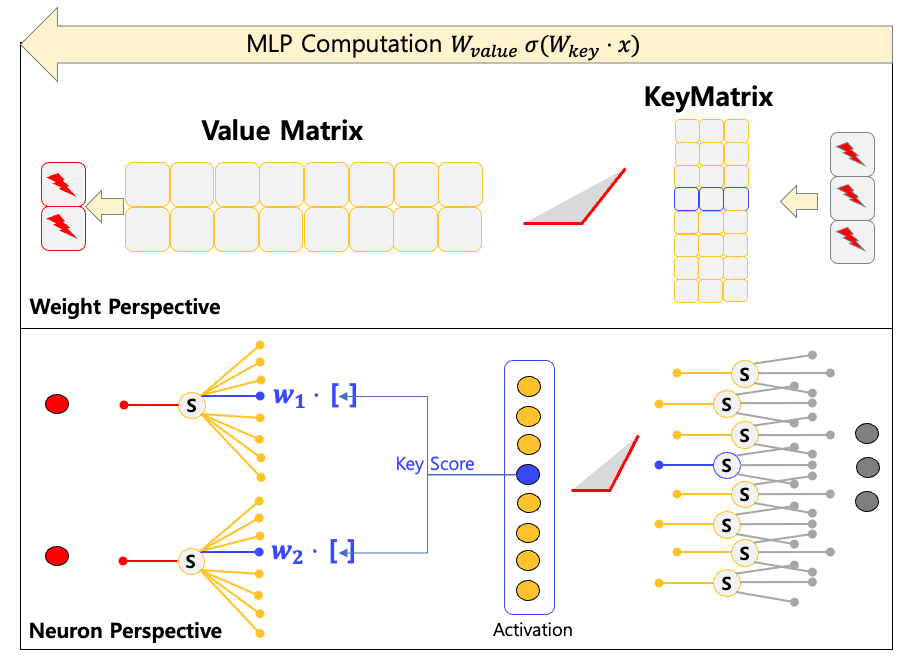
3-4 GPT Block 뉴런
GPT Block 에는 크게 두 가지 모듈이 있다. MLP 와 Attention
MLP
MLP 를 해석하는 방법은 위에서 Linear 를 한 것과 동일하나, 2개를 연속적으로 쌓았다. 두 개의 레이어는 서로 다른 역할을 하는 것으로 알려져 있는데,
첫 번째 레이어는 Key, 두 번째 레이어는 Value이다. Weight의 크기는 GPT 잠재벡터 크기의 4배를 가진다. 예를 들어서,
GPT3 175B는 12,288 의 잠재백터 크기를 가지고 Key Weight은 (49,152, 12,288) 사이즈, Value Weight은 (12,288 * 49,152) 사이즈이다.
이로부터 계산되는 MLP의 뉴런 수는 다음과 같다.
- 📌 (
MLP) 뉴런 개수 : 61,440 = 49,152 (K) + 12,288 (V) - 📌 (
MLP) 뉴런 당 시냅스 개수 : 12,288 (K), 49,152 (V) - 📌 (
MLP) 전체 시냅스 개수 : 1,207,959,552 = 49,152 $\times$ 12,288 (K) + 12,288 $\times$ 49,152 (V)
ATTN
이제 Attention 을 해석해보자.
Query, Key, Value, Output Matrix 의 사이즈는 모두 잠재벡터 사이즈와 동일하다
- 📌 (
ATTN) 뉴런 개수 : 61,440 = 12,288 $\times$ 4 (Q, K, V, O) - 📌 (
ATTN) 뉴런 당 시냅스 개수 : 12,288 (Q, K, V, O) - 📌 (
ATTN) 전체 시냅스 개수 : 603,979,776 = (12,288 $\times$ 4) $\times$ 12,288
블럭 수는 96개이다. 따라서, 블록들로만 구성된 GPT3의 시냅스 수는 다음과 같다.
GPT3
GPT3 는 96개의 GPT Block을 쌓은 결과물이므로 MLP 와 ATTN 을 96개만큼 쌓으면 모델에 존재하는 뉴런과 시냅스 개수를 측정할 수 있다.
- 📌 (
GPT3) 시냅스 : 193B (173,946,175,488 = 96 $\times$ (1,207,959,552 + 603,979,776))195B가 아닌 이유: 블록에 포함된 모듈 중에서 LayerNorm이 Affine Transform 에 파라미터가 존재하고, Embedding과 Unembedding에 파라미터가 존재한다. - 📌 (
GPT3) 뉴런 : 11M (11,796,480 = 96 $\times$(61,440+61,440)) - 📌 (
GPT3) 뉴런 당 시냅스 수 : 14,745
사람의 뉴런당 시냅스의 개수가 7,000개인 것을 생각하면, GPT3 의 경우 뉴런당 시냅스가 2배 정도 더 많은 것을 볼 수 있다. 뉴런당 시냅스의 수가 Hidden dimension 에 비례한 것을 토대로 볼 때, GPT3는 뉴런의 수가 사람보다 적지만 더 많은 뉴런들이 커뮤니케이션을 하는 것으로 생각할 수 있다.
7.4 Key-value