뉴런 - 4. 다중 뉴런 분석
여러 개의 뉴런의 활성화를 동시에 고려하는 방법에 대하여
딥러닝 내부는 많은 파라미터들로 이루어져 있다. 이 파라미터를 좀더 큰 단위로 묶는다면 뉴런이라는 개념을 생각할 수 있는데, 뉴런은 특정한 컨셉이나 패턴에 반응하는 것이 알려져 있다
다중 뉴런에 대한 세팅
뉴런 예시) 비선형모델 $f(x) = W_2 \sigma (W_1 x )$ 모델의 경우, $W_1$ 에서 행의 개수는 뉴런의 개수이고, 열의 길이는 뉴런이 처리하는 정보의 개수이다. 마찬가지로 $W_2$ 에서 행의 개수는 뉴런의 개수이다. 따라서 해당 모델은 전체 $W_2$ 와 $W_1$의 행 길이를 더한 것 만큼 뉴런이 있다.
- 뉴런은 입력의 멀티채널에 대해서 단일 아웃풋을 내보내는 것이다.
(입:CNN 입력 채널 개수 또는 MLP 입력 dimension size, 출:단일 아웃풋) - 딥러닝이 다중 아웃풋을 가질 때, 차원의 개수는 뉴런의 개수이다
딥러닝의 내부 Representation 이 1000차원이라면, 1000개의 뉴런이 있는 것이다. .
(딥러닝 출력: CNN 출력 채널 개수 또는 MLP 출력 dimension size = 뉴런개수) - 뉴런들은 동일한 입력에 대해서 독립적으로 입력을 처리한다
뉴런이 1000개이고, 입력이 100차원이라면, 1000개의 뉴런이 100차원의 정보를 가공하여, 각각 1차원 값을 내보낸다. 결과적으로 1000차원의 출력을 내보낸다. .
Interpretation of Multiple Neurons
다중 뉴런을 분석하는데 있어서, 가장 간단하게 두 개의 뉴런이 하나의 입력을 처리하는 경우를 분석해보자. 이 때, 입력 차원은 1차원과 2차원을 모두 분석한다F $\mathbb{R}$에 대해서 두 개의 뉴런 N 이 독립적으로 $w,b \in \mathbb{R}$ 파라미터를 가지고 입력을 처리하고 두 개의 아웃풋을 내보낸다. 이 때, 아웃풋은 음수와 양수가 모두 가능하다
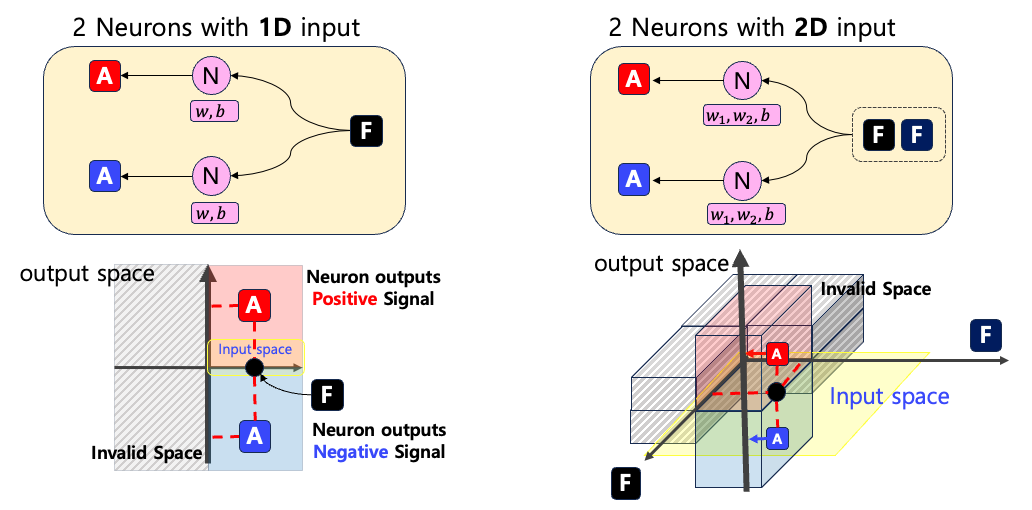
Invalid Space의 경우, 뉴런이 전달받은 값 F는 양수라고 가정하였기 때문에, 음수 영역은 고려대상이 아니다다중 뉴런 분석 시각화
MLP 모델의 임의의 레이어를 분석하는 방법을 살펴보자. 이 때 레이어에 대해서 다음과 같은 가정이 있다.
Linear Layer의 weight $W\in \mathbb{R}^{8\times1}$, bias $b \in \mathbb{R}^{8}$으로, 입력차원은 1차원이고 뉴런의 개수는 8개이다. Torch에서 랜덤하게 Weight을 초기화하고 두 종류의 입력이 있다고 가정하였다.
-
Input 1$= [0.3]$ (약하게 활성화) -
Input 2$= [0.7]$ (강하게 활성화)
아래 그림에서 선들은 각각 뉴런 $n$의 입력 $x$ 값에 따른 활성화값 $y=w_nx+b_n$ 을 나타내는 선이다. 따라서 입력으로부터 뉴런이 어떤식으로 활성화되는지 가이드라인 역할을 하는 선이다 (이는 입력과 무관하다
Input 1 (+) 에 대해서는 3개의 뉴런이 양의 출력을 5개의 뉴런이 음의 출력을 내보냈다. Input 2 (x)에 대해서는 2개만 양수이고 나머지 6개는 음수이다.
Input Boundary
시각화로부터 얻는 정보들
개별 뉴런 (입력에 대한 행동)
선으로부터 얻을 수 있는 정보는 해당 뉴런이 입력에 대해서 어떻게 반응하는지 확일 할 수 있다는 것이다. 예를 들어서, 위 그림에서 Neuron 1 (빨강)의 경우, Weight이 음수이지만 Bias가 양수이므로 작은 입력에 대해서는 양수를 가지며 점차적으로 값이 떨어진다. 이런 식으로 뉴런을 의미를 분석하는 경우, 입력 값의 레벨에 따른 뉴런의 행동을 분석할 수 있다.
문제는 고차원의 경우, 어떤 입력을 바꿔야 하는지 불확실할 수 있다. 왜냐하면, 한 번에 하나의 입력 차원에 대해서 값을 바뀐다면, 입력 차원의 개수만큼 입력 값을 계산해야 한다. 이러한 방법에 대한 해법으로 PCA로부터 얻은 singular vector 방향으로 값을 변하면서 뉴런의 변화를 살필 수 있다
뉴런들의 유사도
선들을 비교함으로써, Weight Vector를 비교함으로써 뉴런들간의 정보처리 유사도가 얼마나 비슷한지 확인할 수 있다. 이게 가능한 이유는 뉴런들간의 입력이 모두 동일하다고 가정했기 때문이다. 뉴런에는 추가적으로 Bias 정보가 있는데, 뉴런간의 비교를 위해서는 각 정보를 각가 비교할수도 있고, 한꺼번에 비교할 수도 있다.
- Weight Vector만 비교 : Weight 은 입력의 레벨에 따라서, 뉴런의 상태가 얼마나 빨리 어느 방향으로 바뀌는지를 비교해준다.
- Bias만 비교 : 뉴런의 값이 기본적으로 얼마나 높은 상태에 있는지 비교한다. Bias 가 크다면 입력값에 의존적이지 않고 항샹 시그널을 보내는 뉴런이다.
- Weight과 Bias를 모두 비교 : 입력값에 따라서 실제로 뉴런값이 어떻게 변하는지 비교한다.
입력에 레벨에 따른 뉴런 그룹
입력 축에 대해서 값을 변경하면서, 뉴런이 활성화되는 지점을 나눌 수 있을 것으로 보인다. 즉, 입력 영역을 뉴런의 값이 변하는지의 여부에 따라서 나누는 것이다. 이는 뉴런들간의 그룹이 입력의 수준에 대한 함수로 작성될 수 있다는 것을 암시한다.
\[\mathcal{G}: F \rightarrow \{ 1,2,\cdots, N \}\]여기서 $\mathcal{G}$는 뉴런들을 묶는 방식에 대해서 사전에 정의한 방법을 따르면 된다. 예를 들어서, 양수의 출력만을 내보내는 뉴런들을 선택할 수 있다. 예를 들어서, 입력의 부분공간 $S \subset F$에 대해서 다음과 같은 함수 맵핑을 생각할 수 있다. 입력의 부분공간을 다룰 수 있는 이유는 입력값이 연속적이고, 뉴런의 활성화는 선형모델이므로 이 또한 연속적이기 때문이다. 아래 예시를 살펴보자.
예시)
입력공간 $F = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8]$
뉴런들 $\mathcal{N} = [1,2,3,4,5,6,7,8]$
그룹 함수들에 대해서 다음과 같은 맵핑을 생각할 수 있다.
$\mathcal{G}_1$ : 뉴런 값이 양수인 뉴런들
$S_1=[0.1, 0.2, 0.3] \underset{\mathcal{G}_1}{\mapsto} [1,2,8]$
$S_2=[0.4, 0.5] \underset{\mathcal{G}_1}{\mapsto} [3,4]$
$S_3=[0.6, 0.7, 0.8] \underset{\mathcal{G}_1}{\mapsto} [5,6,7]$
$\mathcal{G}_2$ : 뉴런 값이 양수이면서 데이터셋의 활성화에서 Q4 이상으로 양수인 경우
$S_1=[0.1, 0.2] \underset{\mathcal{G}_2}{\mapsto} [1,2,8]$
$S_2=[0.4] \underset{\mathcal{G}_2}{\mapsto} [3,4]$
$S_3=[0.6] \underset{\mathcal{G}_2}{\mapsto} [5,6,7]$
Discussion
위 분석에서는 뉴런의 입력이 1차원이라고 가정하였다. 그러나, 대부분의 딥러닝 모델의 차원으 1보다 훨씬 크다. 그럼에도 불구하고 1차원 분석을 해야 하는 이유는 100차원 입력 분석이 1차원적분석의 확장판이 될 가능성이 크기 때문이다. 또한, 적어도 1차원에서 분석할 수 있는 모든 것들을 끝낸다면, 더 높은 차원들에 대해서 뉴런의 행동을 연구할 수 있을 것 같다.
