Investigating Instability of Messages in
Multi-agent Reinforcement Learning
Stability analysis of hidden representation messages in multi-agent.
Introduction
Environment is a complex space where several agents and objects make interactions. In the environment, rational agents act to maximize utilities and the action is learned by reinforcement learning algorithm (RL) with a deep neural network. As the most of environments are non-stationary, a single agent can not achieve the maximum utility only with its observation and inferences with a network. However, if multiple agents can communicate with each other, a single agent can get richer information about the states of the environment by simply obtaining messages from other agents. However, the inferred information from other agents are made by a neural network which is sometimes vulnerable and includes the personal perspective of the agent processed the information. For example, even though there is a single observation, two agents can encode very different messages as parameters and modules could be different.
Therefore, it is important to consider the subjectivity of messages in multi-agent reinforcement learning (MARL). Based on the assumption that the encoded information is a rather subjective information of the agent encode it, we tackle the problem of handling objective and subjective information in MARL. One limitation is that the processed information by a neural network is hardly interpreted. As the starting work of this subjectivity work, we tackle the most minor problem whether the subjective information is better than the objective information. In detail, we compare the usefulness of messages from an agent to another agent in two kinds: raw observation and the output of a neural network.
Related Work
Before proceeding, we review the previous methods in MARL.
Learning Shared Q-values
QMIXlearns a mixing network of Q-values which outputs the mixed Q-value which is monotonically increasing for agent Q-values. MADDPG utilizes the Q-functions conditional on broad casted information from agents and execute agents in decentralized manner with the learned policy conditioned only on the observation of each agent.
MAPPO (Multi-agent PPO)utilizes the PPO with centralized value function inputs, while the value function of IPPO (Independent PPO) takes an independent input.
Communication Skills
TarMacutilizes the attention mechanism between agents to spread the values between communicated agents. The recurrent hidden states outputs two components query and [key, value] vectors. I2C uses the prior network to determine whom to request a message. The difference with TarMac is the separation of communication steps. We believe I2C is discrete as due to the determination of agents to communicate. Note that TarMAC is based on Q-K communication.
Modeling What to Share
LToSis a hierarchical modeling of agents (bi-level optimization) where the high-level policy distributes the reward signals to neighbors and the low-level policy control agent each. The shared information is the reward of each agent and the information can benefit the cooperative MARL.
Note that our problem is in the field of Communication Skills and Modeling What to Share, and is orthogonal to the previous methods as we design the package style rather than communication styles.
Proposed Method
Several MARL methods consider how to communicate between agents and make message with a deep neural network (DNN). As the output of the DNN automatically formed with the optimization algorithms, it is natural to think that the output of the agent is a compact information necessary to communicate between agents well. However, as the deep neural network is hardly interpreted, the passed message could be ambiguous and sometimes include errors. On the other hand, the observation of the agent is most unprocessed information which does not include the knowledge of the agent. Within the progress of the interpretation of DNN, we can find that the neurons in DNN are firing when they capture features in an observation.
We believe that the simplicity of the observation is necessary for the message, but the message may include some errors induced from the agent. Therefore, the receiver of the message may distinguish two information to decide whether to accept the processed information or decline it.
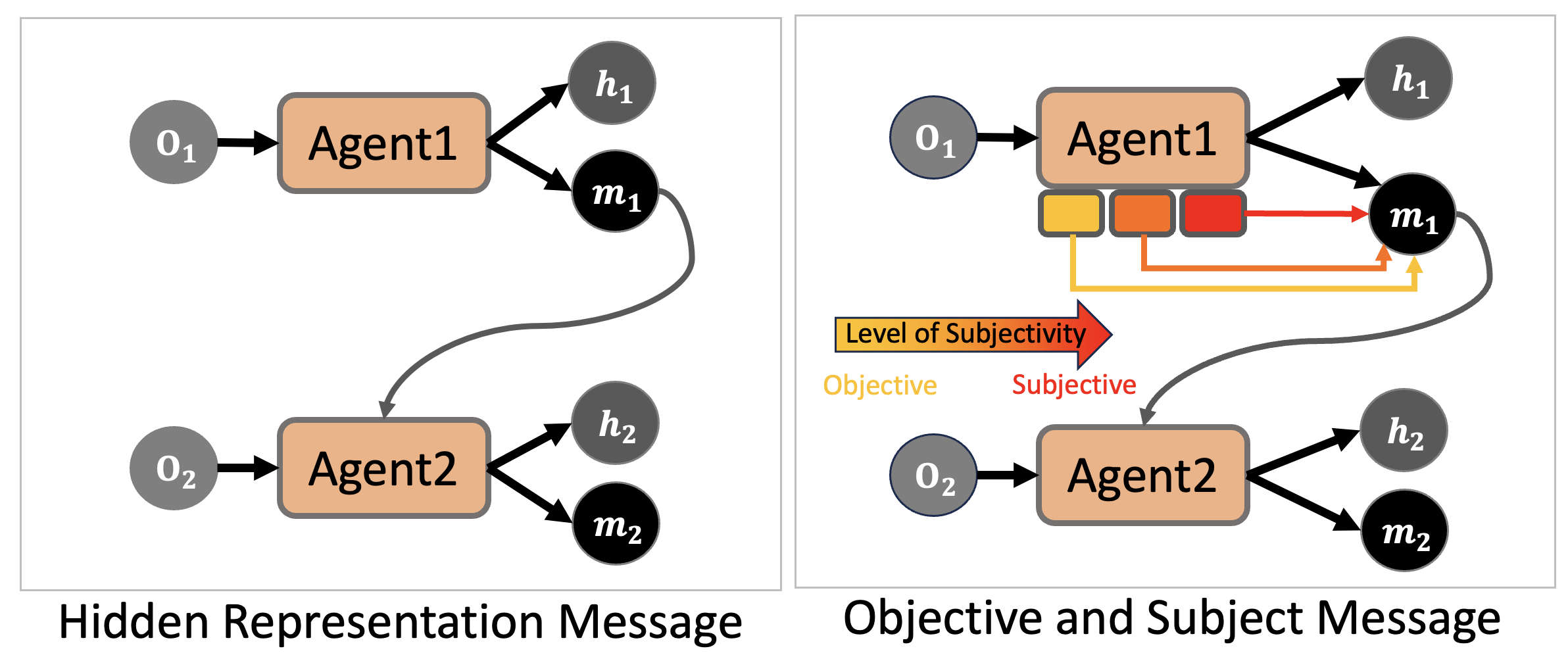
Why Subjectivity
The general belief of a DNN is that the hidden representation is a compact representation of the input. Therefore, it may not be necessary to gather information based on the subjectivity.
However, the recent progress in the interpretability field have found that the internal neurons are activated by specific patterns and they form circuits for complex features
Message Passing with Deep Neural Network
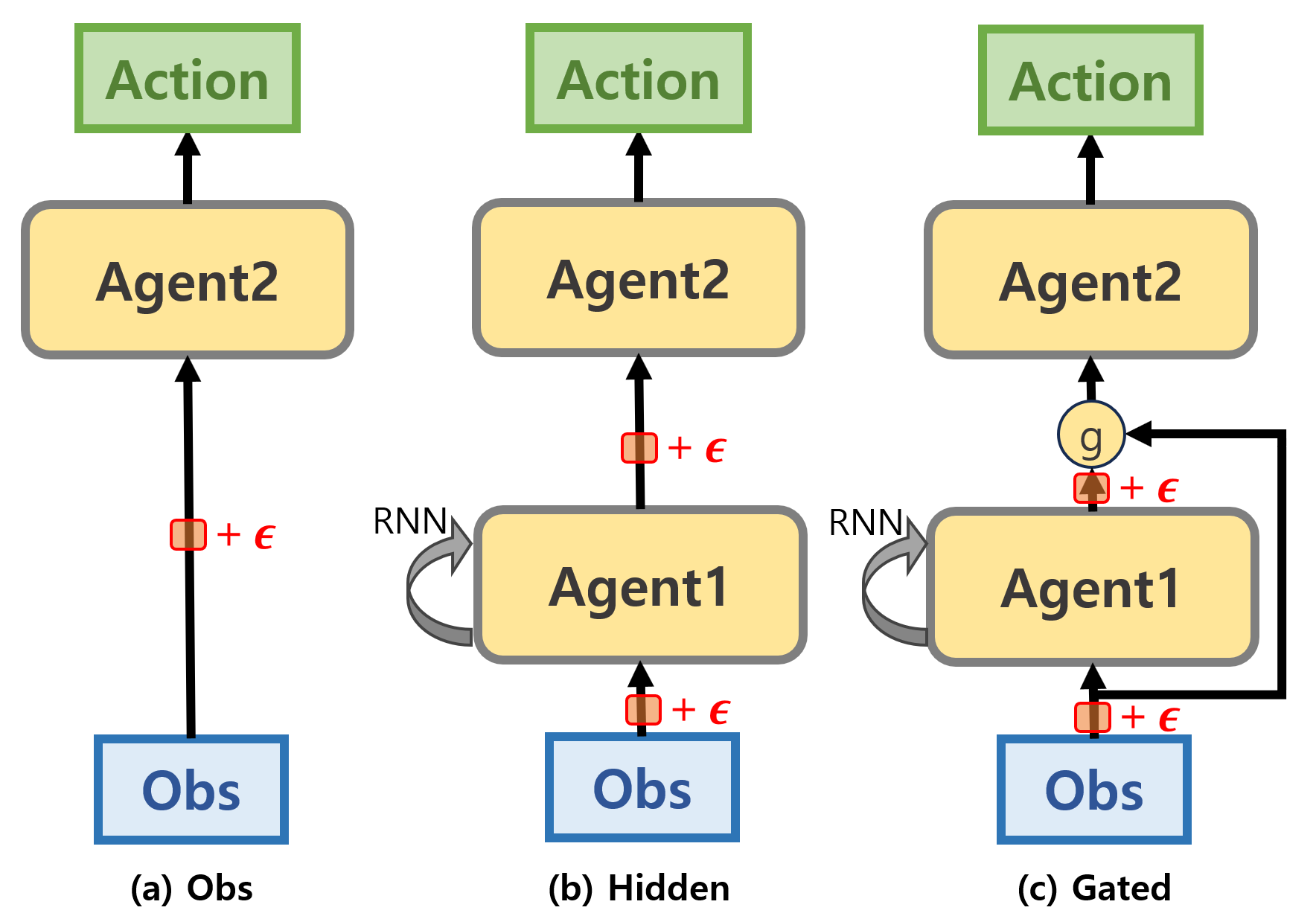
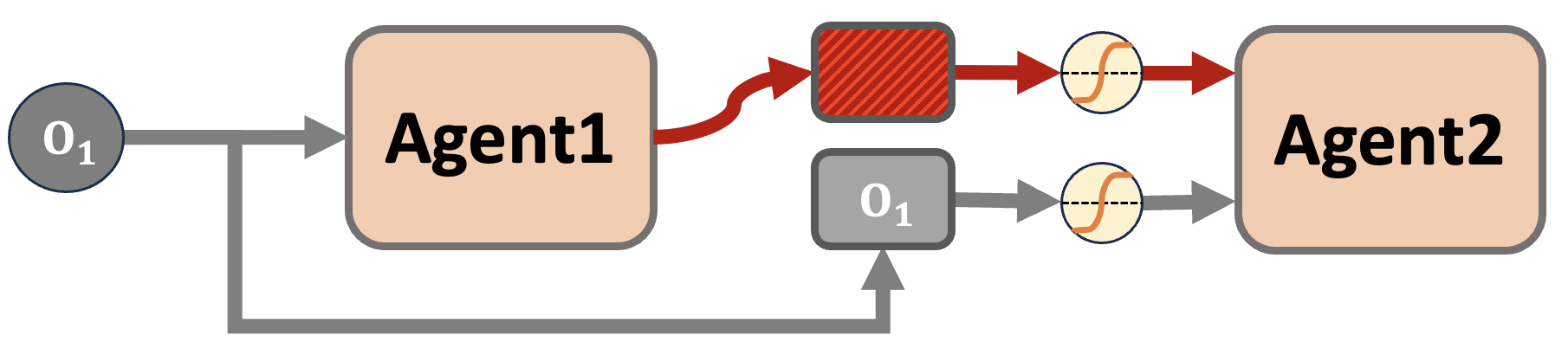
In this work, we propose gated message passing in the communication of multi-agent. Although the agents are trained with the RL framework to determine the action, the passage passing could be simply modeled with representation passing optimized by the behavior of the receiver agent. That is, the pipeline has an observation of the sender agent as input and the action of the receiver agent as output. Consider agent (s) as a sender and agent (r) as a receiver.
Let $o_t^{(s)} \in \mathbf{R}^{obs}$ be the observation of sender agent at time step $t$ and $h_t^{(s)} \in \mathbf{R}^d$ be the hidden message made by sender agent. The sender agent will pass both information $(o_t^{(s)},h_t^{(s)})$ to the receiver agent who will choose which information to take with gating scalar $\sigma^{(r)}$ to produce the processed message $g_t^{(r,s)}$.
\[g_t^{(r,s)} = \sigma_t^{(r)} h_t^{(s)} + (1 - \sigma_t^{(r)}) \hat{o}_t^{(s)}\]where $\hat{o}$ is a linear transformation of observation $o$ to match the dimension with hidden representation.
Noised Message Testing
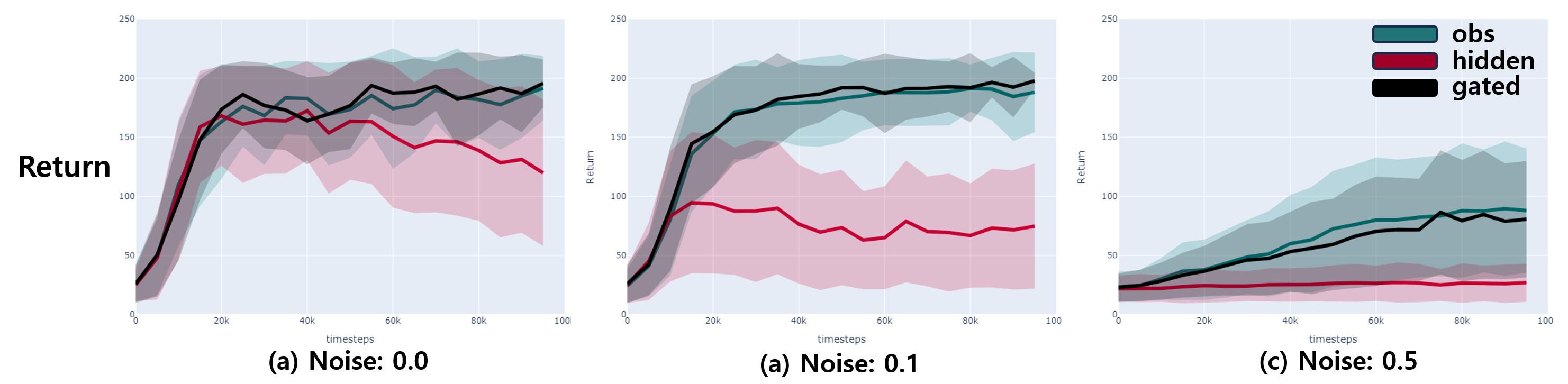
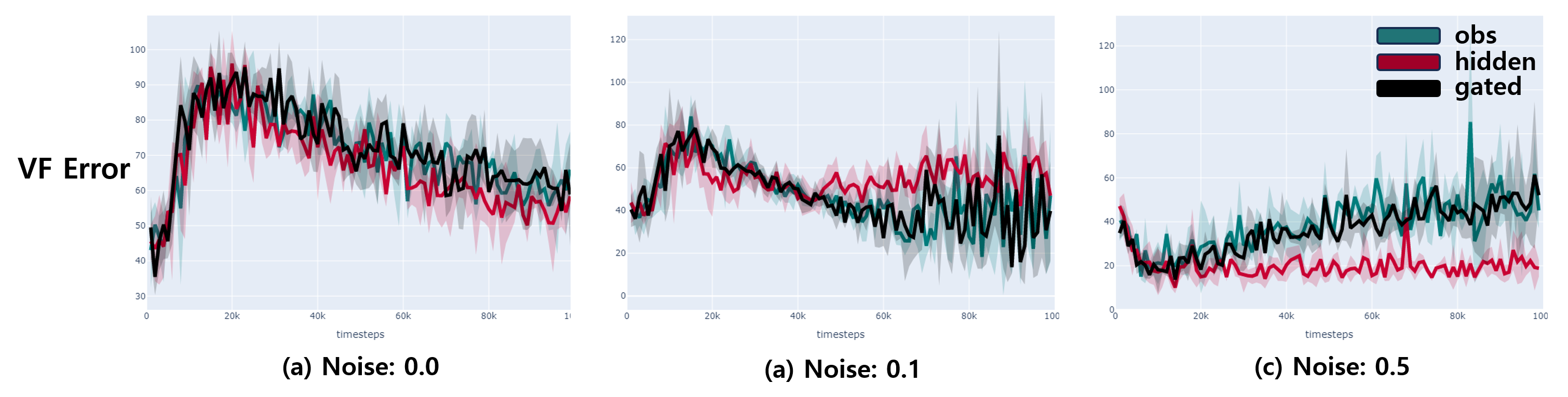
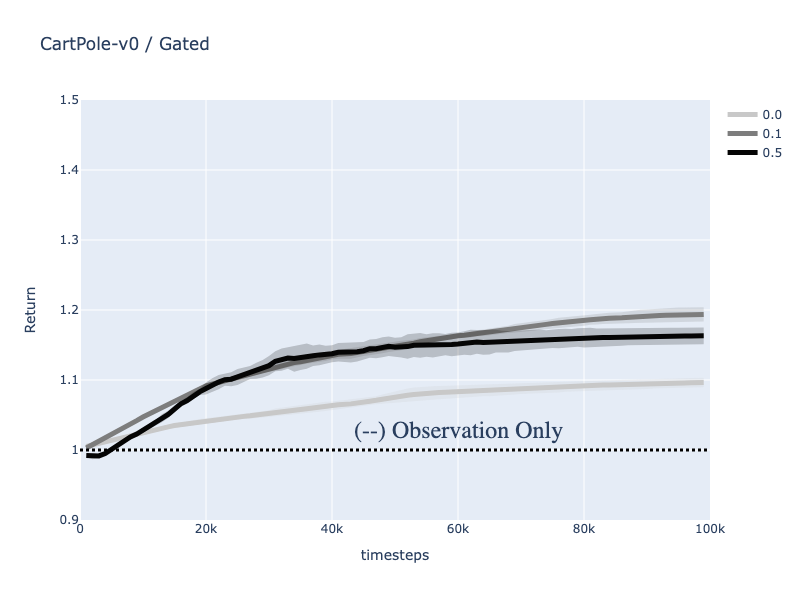
To test the effectiveness of the gating mechanism in message passing. We conduct simple observation passing settings. We train a single agent in RL with directly separate modules: Agent1 and Agent2. The Agent 2 processes the raw observation at the current time step with MLP, while Agent 2 processes the observation with RNN with hidden representations. In addition, we added noises to test the robustness of messages. The Figure below shows three types of message passings: (a) Is the case when the agent has only MLP to process the current observation, (b) is the case when RNN is applied to process the long horizontal information, and (c) is the gated neural network. Note that we add noise sampled from normal distribution in two parts: observation and hidden representation to test robustness.
The Figure below shows the return averaged over 2 seeds. We observe that the gated agent has competent performance with the raw observation case, while hidden representation fails as the noise increases. These results indicate that the noise significantly hurt the performance.
To further provide analysis, we track the interpolation value while training. The result shows that the interpolation value increases from 1 to 1.2 which means the neural network learned to add hidden representations over training. Note that 1 is the initialized value which is the circumstance that the agent takes only the observation.
Message Passing in Multi-Agent
To further verify the effectiveness of gated message passing, we compare three modelings in multi-agent environment.We use MATE

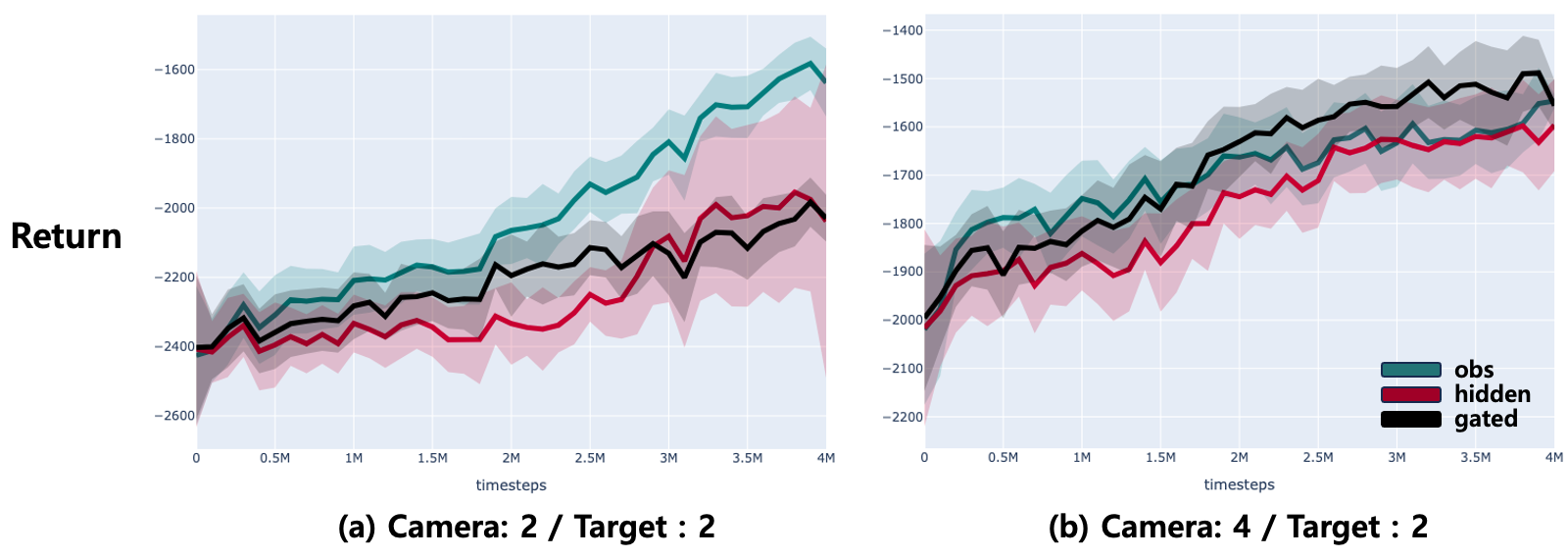
In the environment, multi-agent communicate with each other with TarMAC model which computes attention scores to pass a hidden message generated from RNN. We designed a gated mechanism in the receiver agent which determines the ratio between a hidden representation or a raw observation (see the Figure below). We test two settings, 4vs2 and 2vs2 where the first number is the number of cameras and the second number is the number of targets.
The Figure below shows the training return over 4M time steps. The results showed that the gated message passing is effective when there are many agents (4vs2), while remaining similar performance in the small number of communications (2vs2). In addition, the 95% confidence region is very huge for hidden representation which indicates that the messages originated from a deep neural network could be unstable.
Conclusion
This work propose a gated message passing in multi-agent communication to mitigate the effect from unstable messages in deep neural network. Our work show that the message passing starting from raw observation and slightly adding hidden representation messages is an effective way of communication.
